Conquer Your Big Data
Spark SQL is a powerful tool within the PySpark ecosystem designed for efficiently querying and manipulating structured data at scale. It allows you to leverage familiar SQL syntax on massive datasets distributed across a cluster, making big data analysis accessible and efficient.
Unveiling Spark SQL
Spark SQL acts as a bridge between relational databases and the distributed processing power of Apache Spark. It provides a programmatic interface for:
- Structured Data Processing: Spark SQL represents data as DataFrames, similar to traditional database tables. This structured format allows for efficient querying and manipulation using SQL-like operations.
- SQL Integration: Spark SQL understands a wide range of SQL functionalities, including filtering, joining, aggregation, and subqueries. This familiarity makes it easy for SQL users to transition to working with big data.
- Integration with PySpark: Spark SQL seamlessly integrates with other PySpark functionalities. You can leverage Spark SQL for data cleansing and transformation before analysis, all within the same environment.
Putting Spark SQL to Work: An Example
Let's delve into a practical example: Imagine you have a massive dataset containing customer purchase information. You can use Spark SQL to:
Load Data:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("Spark SQL in PySpark").getOrCreate()
customer_data = spark.read.csv("customer_data.csv")
Filter Customers by City:
filtered_customers = customer_data.filter(customer_data.city == "New Delhi")
Calculate Total Sales:
total_sales = filtered_customers.groupBy("product_category").sum("purchase_amount")
This simple example demonstrates how Spark SQL can be used to manipulate and analyze large datasets through familiar SQL-like commands.
Mind Mapping Your Spark SQL Journey
To master Spark SQL effectively, here's a mind map encompassing key concepts:
- DataFrames and Datasets: Understanding the fundamental data structures used by Spark SQL for storing and manipulating data.
- SQL Operations: Mastering core SQL functionalities like filtering, joining, aggregation, subqueries, and window functions.
- Data Loading and Saving: Exploring various methods for loading data from different sources (CSV, JSON, Parquet) and saving results.
- User-Defined Functions (UDFs): Creating custom functions to extend Spark SQL's capabilities for specific data manipulation needs.
- Spark SQL Optimization: Learning techniques to optimize your Spark SQL queries for faster performance on large datasets.
- Integration with Other PySpark Modules: Understanding how Spark SQL interacts with other PySpark modules like Spark MLlib for machine learning tasks.
Examples to Spark Your Learning
Beyond the basic example, here are some practical applications of Spark SQL:
- Analyzing website log data to identify user behavior patterns.
- Joining customer data with product information for targeted marketing campaigns.
- Performing large-scale data aggregations for business intelligence reports.
- Cleaning and preparing big data for machine learning pipelines.
These examples showcase the versatility of Spark SQL in real-world big data scenarios.
Finally, To recall all the concepts in Spark SQL
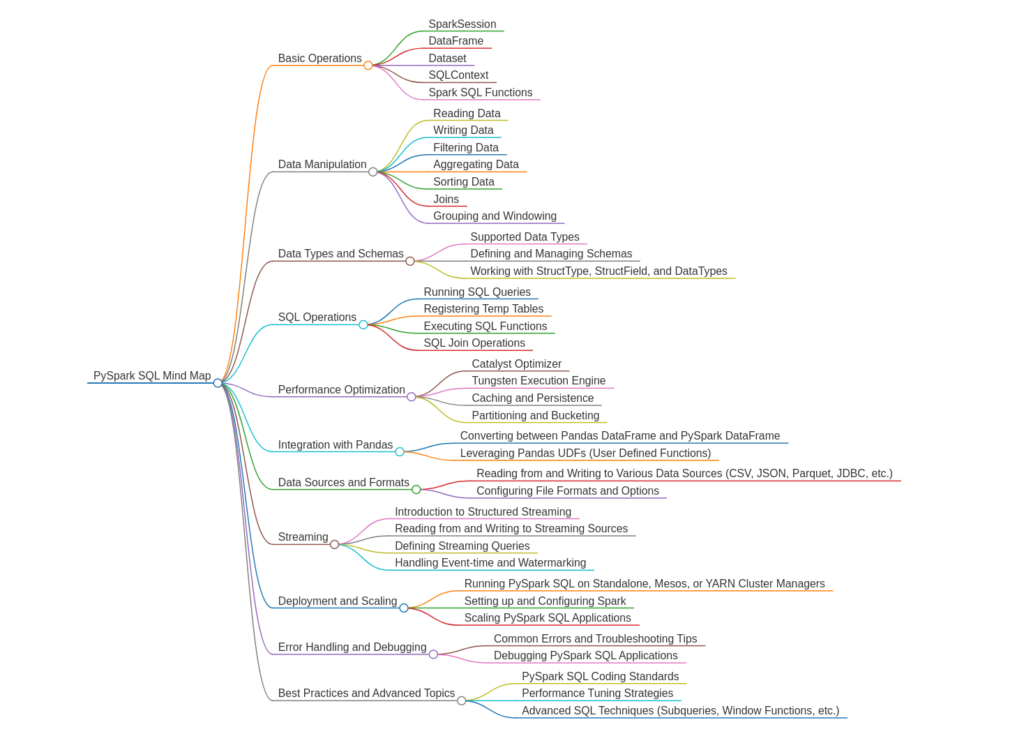
By understanding the core concepts, practicing with various examples, and exploring advanced functionalities, you can unlock the power of Spark SQL and become a master of big data manipulation in the PySpark ecosystem.