Understanding Narrow and Wide Transformations in Apache Spark
What is Spark Transformation ?
Spark transformations are operations that create new Resilient Distributed Datasets (RDDs) from existing ones.
RDDs are the fundamental data structure in Spark, and they represent a collection of partitioned data that can be processed in parallel across a cluster of machines.
Transformations are lazy, meaning that they do not actually compute their results until an action is triggered. This allows Spark to optimize the execution of your program by only computing the data that is actually needed.Types of Spark Transformations.
Spark provides a range of transformations and actions that can be performed on Resilient Distributed Datasets (RDDs) and DataFrames. Two important transformations in Spark are the narrow and wide transformations.
In this article, we will understand the concepts of narrow and wide transformations in Spark and the difference between the two.
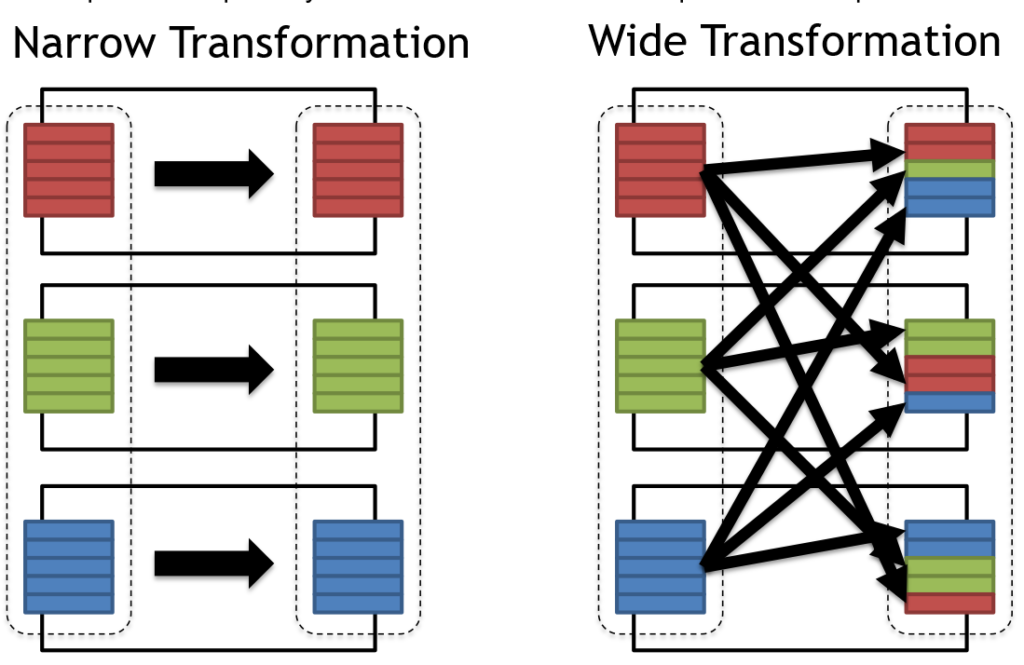
Narrow Transformations in Spark
Narrow transformations are transformations in Spark that do not require shuffling of data between partitions. These transformations are performed locally on each partition and do not require any exchange of data between partitions.
- These are transformations that operate on a single partition of the RDD/DataFrame at a time.
- Examples: map(), filter(), flatMap()
- These are more efficient since they don’t require data movement across partitions.
Wide Transformation:
- These are transformations that require data movement and shuffling across partitions.
- Examples: groupByKey(), reduceByKey(), join(), repartition()
- These are more expensive operations since they involve network I/O and data shuffling.
Here is an example of how to use Spark transformations:
spark.read.text(“Myfile.txt”)
.filter(line -> line.contains(“Shekar”))
.map(line -> line.toUpperCase())
.count()
>>> strings = spark.read.text(“Myfile.txt”)
>>> filtered_text = strings.filter(strings.value.contains(“Shekar”))
>>> filtered_text.count()
9
This code will read a text file called “Myfile.txt”, filter the lines to only include those that contain the word “foo”, convert the lines to uppercase, and then count the number of lines
Other Types of Transformations
In addition to narrow and wide transformations, there are a few other types of transformations that are worth mentioning:
Actions:Actions are operations that return a value to the driver program. Actions trigger the execution of the transformations in a Spark program.
Caching:Caching an RDD tells Spark to persist the RDD in memory so that it can be reused later. This can improve the performance of subsequent operations.
Repartitioning: Repartitioning an RDD changes the number of partitions in the RDD. This can be useful for improving the performance of certain operations, such as join.
Images to Understand Spark Transformations
Very good article. Simply explained this concept