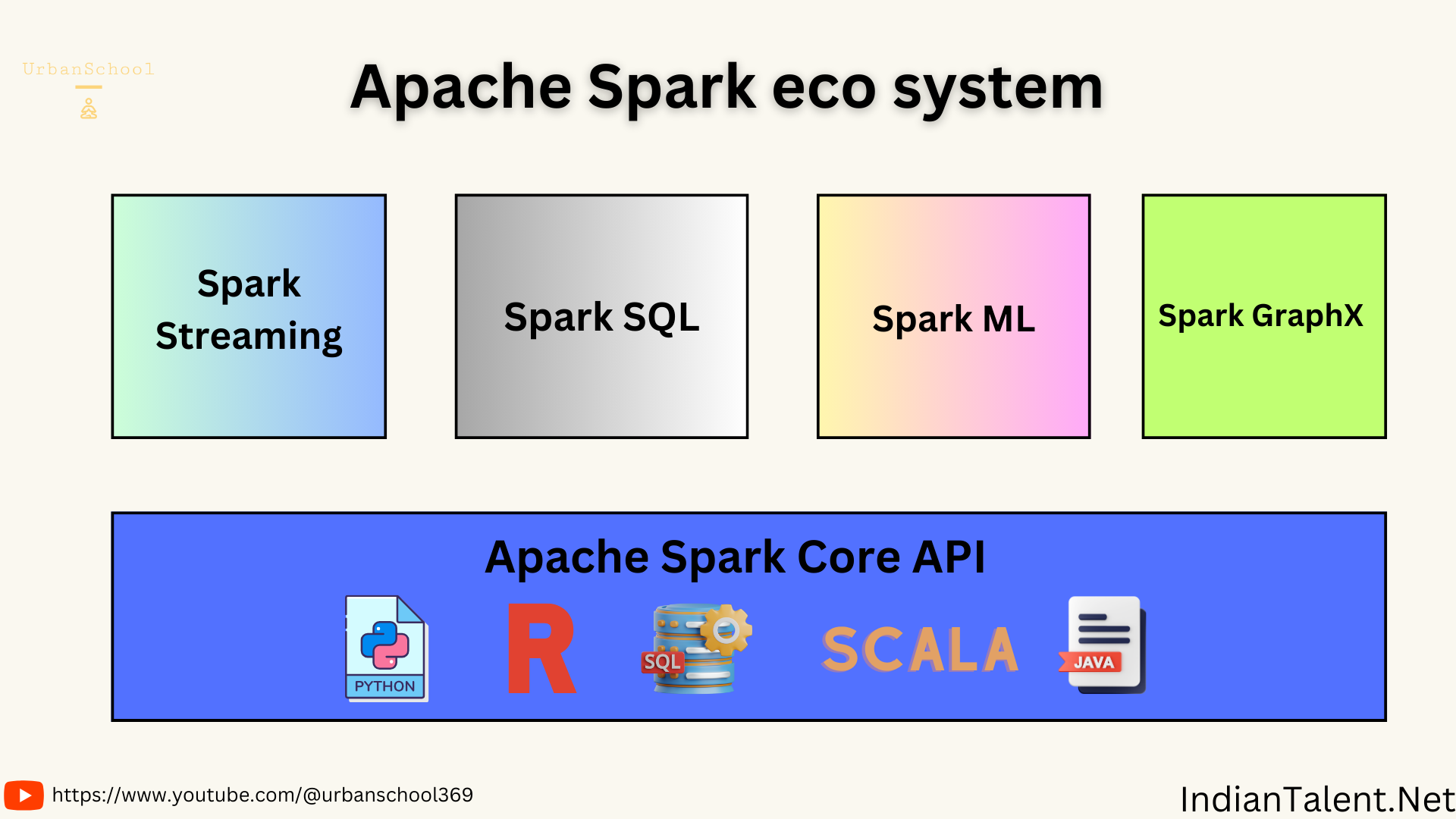
As a data engineer, getting familiar with Apache Spark is invaluable given its dominance for large-scale data processing. Spark provides a unified engine with several modules for different workloads. In this post, I’ll dive deeper into key modules that make up the Spark ecosystem and the core concepts that power its distributed computing capabilities.
Spark Core
Spark Core contains the basic functionality of Spark including components for task scheduling, memory management, fault recovery, interacting with storage systems and more.
As data engineers, key concepts to understand are
- RDDs (Resilient Distributed Datasets) - The basic abstraction in Spark that represents an immutable collection of data partitioned across nodes. Allows applying operations in parallel.
- Directed Acyclic Graph (DAG) - The logical execution plan for a Spark job that allows for lazy evaluation and optimization.
- In-memory processing - Spark tries to process data in memory instead of on disk which makes applications 10-100x faster. The Spark execution engine handles moving data into memory.
Spark SQL
The SQL module and DistributedSQL engine allows engineers to expose Spark data through a tabular format and query large datasets using ANSI SQL. Key abilities enabled by Spark SQL:
- Query structured and semi-structured data using familiar SQL syntax
- ETL and data preparation using DataFrames which are distributed tabular datasets
- Connectivity to many data sources such as Hive, Avro, Parquet, ORC
Spark Streaming
Spark Streaming makes processing real-time data a breeze via its high-throughput, fault-tolerant stream processing engine. Key concepts include:
- Processing using micro-batch architecture, to simplify stream processing semantics
- Easy integration with popular streaming data sources like Kafka and Flume
- Immutable, partitioned streams that make replication and data recovery simpler
MLlib & GraphX
MLlib contains common machine learning algorithms optimized to run distributedly on Spark. GraphX brings graph processing to graph-structured data.
By getting comfortable with these modules and leveraging the computational power of Spark, we can build highly scalable data engineering solutions. Understanding key architectural concepts like distributed datasets, in-memory processing and lazy evaluation helps unlock Spark’s true potential.